«Палех» - новый поисковый алгоритм от Яндекса

В ноябре 2016 года, компанией Яндекс был представлен поисковый алгоритм, который называется «Палех». Для реализации этого алгоритма использовались искусственные нейронные сети.
«Длинный хвост» поисковых запросов
Ежедневно поиск Яндекса отвечает в среднем на 280 миллионов запросов разной частотности, часть которых вводится практически ежесекундно, а другие настолько уникальны, что могут больше не повториться. Визуально распределение частотности запросов можно представить в виде Жар-птицы (сказочный персонаж, который встречается на палехских миниатюрах – отсюда и название алгоритма).
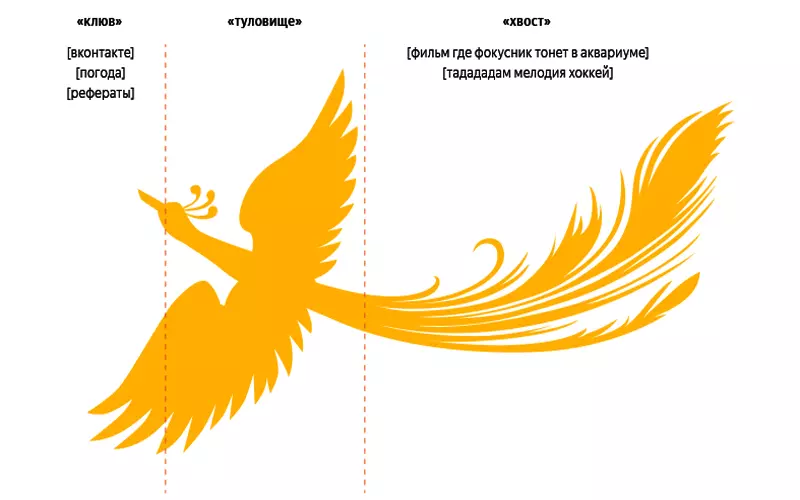
Запросы, которые задают очень часто (их небольшое количество), образуют «клюв» птицы. Те запросы, у которых средние количество и частотность, составляют «туловище». Низкочастотные запросы, встречающиеся крайне редко по отдельности, вместе образуют «длинный хвост» - они являются большей частью поискового потока (таких запросов вводят около ста миллионов ежедневно).
Так как запросы из «длинного хвоста» пользователи задают реже остальных, то отслеживание статистики поведения по ним представляется трудной задачей. Из-за этого поисковой системе трудно понять то, какие сайты могут соответствовать таким запросам, а какие нет. Для того чтобы поиск мог лучше обрабатывать «длинный хвост» запросов, Яндекс создал новый алгоритм, для разработки которого были привлечены искусственные нейронные сети.
Искусственные нейронные сети и семантический вектор
Искусственные нейросети нашли свое применение в различных задачах машинного обучения. Сеть можно научить распознавать какие-либо объекты, например изображения. Во время обучения, сети показывают набор картинок. Одна часть этого набора содержит нужные для распознавания объекты (положительный пример), а другая не содержит (отрицательный пример). После обучения, нейронная сеть способна определять необходимые объекты на разных изображениях.
В случае с поисковыми запросами, приходится иметь дело не с изображениями, а с текстами (запросов и заголовков). Обучение нейросети происходит по тому же принципу положительных и отрицательных примеров. В качестве примера здесь выступает пара «запрос-заголовок».
Так как компьютеру проще работать с числами, то разработчиками было принято решение обучить нейронную сеть переводить заголовки веб-страниц, известные Яндексу, в группы из трехсот чисел. В результате документы из базы Яндекса получили координаты в трехсотмерном пространстве.
В виду того, что такое многомерное пространство представить довольно трудно, в качестве примера можно рассмотреть двумерное пространство. В этом случае каждое число будет координатой одной из двух осей, а веб-страница будет соответствовать точке на координатной плоскости.
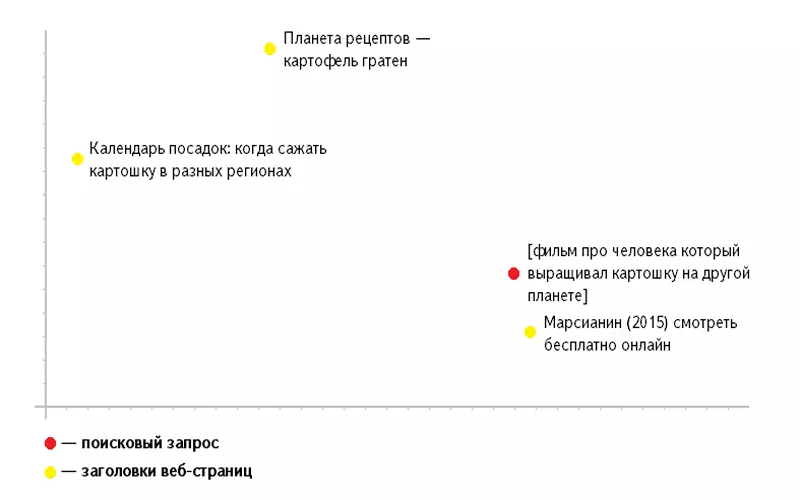
По тому же принципу, текст запроса переводится в числовой набор, т.е. запрос помещается в то же пространство координат, что и заголовок веб-страницы. Суть такого представления состоит в том, что чем ближе координаты поискового запроса и заголовка будут располагаться друг к другу, тем релевантнее будет страница. Такой способ сопоставления запроса с вероятными ответами называется «семантическим вектором».
Таким образом, семантические векторы позволяют лучше находить соответствующие запросу страницы при отсутствии поведенческой статистики.